
In the ever-evolving field of artificial intelligence, deep neural networks (DNNs) have become a cornerstone technology. From image recognition to voice recognition, it is essential for creating advanced AI. One of their most outstanding applications is large language models (LLMs) such as GPT or BERT, that rely on highly sophisticated neural network architectures for processing and generating near-human speech. These LLMs are essentially scaled-up, specialized DNNs with billions of parameters, fine-tuned to handle natural language understanding and generation tasks.
Next, we would look into the anatomy of deep neural networks and their training process.
1. Let’s start with the Basics
1.1 What is a neural network?
Neural networks, also referred to as artificial neural networks or simulated neural networks, form a subset of machine learning and constitute the backbone of deep learning algorithms. The term “neural” is derived from the fact that the networks are designed to mirror a neuron in the brain signaling to one another.

Neurons are nerve cells found in the brain. These cells are connected to each other by nerve extensions, which allow electrochemical impulses to flow through the network. The input signal is analyzed by the network’s first neuron upon stimulation, and if it surpasses a specific threshold, the neuron is activated and transmits the signal to the neurons it is connected to. The signal may then travel across the rest of the network when these neurons are triggered. As you become proficient at responding, regular use strengthens the connections between the neurons.
For instance, your neural connections allow you to receive visual information and coordinate your motions to catch a ball thrown towards you. The network of neurons involved in catching a ball will become stronger as you practice this activity over time and learn how to get better at it.
Artificial neural networks that process numerical inputs instead of electrochemical stimuli are used in deep learning to mimic this biological process.
A neural network consists of node layers-an input layer, one or more hidden layers and an output layer. Each node is an artificial neuron connecting to a different node.
The incoming node connections correspond to numeric inputs that are typically identified as x. When there’s more than one input value, x is considered a vector with elements named x1, x2, and so on.
Associated with each x value is a weight (w), which is used to strengthen or weaken the effect of the x value to simulate learning. Additionally, a bias (b) input is added to enable fine-grained control over the network. During the training process, the w and b values will be adjusted to tune the network so that it “learns” to produce correct outputs.
Each node encapsulates a function that calculates a weighted sum of x, w, and b. This function is in turn enclosed in an activation function that constrains the result (often to a value between 0 and 1) to determine whether or not the node passes an output onto the next layer of nodes in the network. If the output of one node becomes larger than the threshold, it activates and sends data to the next layer. If it’s less than that, no data is transmitted.
Neural networks learn and improve their accuracy over time with the help of training data. Once the learning algorithms of a well-tuned instructional unit are created, they will soon become powerful computer science and AI tools as they rapidly enable data analysis and clustering simultaneously.
1.2 Then what’s the difference between “deep” neural networks and neural networks?
Neural networks can be divided in two groups: Shallow and Deep neural networks.
A shallow neural network is an artificial neural network characterized by its simple architecture, typically consisting of an input layer, one or two hidden layers, and an output layer. This minimal structure makes shallow networks less computationally intensive and easier to train compared to their deep network counterparts, making them suitable for tasks with simpler relationships between inputs and outputs, like linear regression, binary classification or feature extraction (embeddings).
While shallow neural networks can effectively handle straightforward prediction tasks, they may not perform as well on complex problems that require hierarchical feature extraction. Such complex tasks are often better addressed by deep neural networks, which have multiple hidden layers that allow them to capture more intricate patterns in the data.
As mentioned in the explanation of neural networks above, but worth noting more explicitly, the “deep” in deep learning refers to the depth of layers in a neural network. A neural network of more than three layers, including the inputs and the output, can be considered a deep-learning algorithm. That can be represented by the following diagram:
1.3 So, is deep learning and deep neural network (DNN) the same thing?
The terms deep learning and deep neural network (DNN) are closely related but not identical. Here’s the distinction:
| Deep Learning | Deep Neural Network | |
|---|---|---|
| Definition | Deep learning refers to a subfield of machine learning that focuses on using algorithms inspired by the structure and function of the human brain, specifically deep neural networks. | A DNN is a specific type of deep learning model characterized by multiple layers of neurons, including an input layer, one or more hidden layers, and an output layer. |
| Scope | It is the broader field encompassing concepts, methodologies, and applications involving multi-layered architectures (such as DNNs, convolutional neural networks (CNNs), and recurrent neural networks (RNNs)). | It is a practical implementation or model used within the broader field of deep learning. |
| Purpose | It emphasizes training models to learn complex patterns and representations directly from data, often requiring significant computational resources and large datasets. | Designed to perform tasks like classification, regression, and feature extraction by learning hierarchical patterns. |
1.4 What about LLMs? How are they connected?
- An LLM is fundamentally a kind of DNN. It is made up of numerous layers of neurons that are intended to learn intricate data representations. These layers in LLMs are extremely specialized to deal with textual data.
- A DNN employs fully connected layers, which are adequate for a general-purpose task, whereas LLMs include sophisticated methods such as transformers. These include mechanisms like self-attention to understand relationships between words, phrases, and context over long sequences.
- Built on top of transformers, LLMs are basically very big DNNs with billions or perhaps trillions of parameters. This opens an avenue for more sophisticated natural language understanding and generation tasks.
- While both DNNs and LLMs are trained on similar principles – forward propagation, back propagation, gradient descent – LLMs are usually pre-trained on huge text corpora and fine-tuned to a specific task.
- While a regular DNN would classify images as either a “cat” or numerical output, the advanced DNN foundations help LLMs do high–end operations such as summarization, translation, and text generation.
2. The Architecture of a Deep Neural Network
A typical DNN consists of three primary components:
- Input Layer: This layer serves as the entry point, where raw data (e.g., pixel values, text embeddings) is fed into the network.
- Hidden Layers: These layers extract features and build hierarchical representations of the data. Each hidden layer transforms the input using weights, biases, and activation functions.
- Output Layer: The final layer produces predictions, classifications, or other outputs.
Let’s break this down with a real-world scenario: identifying objects in an image (e.g., recognizing a dog in a photograph).
Input Layer
Raw image pixels (e.g., 128×128 grid, flattened).
Output: Forwarded to the first hidden layer
First Hidden Layer
Detects low-level features like edges or textures.
Output: Feature maps (e.g., edges, corners)
Middle Hidden Layers
Identify higher-level patterns, such as shapes.
Output: Abstract patterns (e.g., curves, shapes)
Deeper Hidden Layers
Recognize specific objects, like a dog.
Output: High-level features (e.g., the dog’s shape, texture)
Output Layer
Predicts the category with the highest probability.
Output: Class probabilities
3. Training a Deep Neural Network
Before discussing the training and fine-tuning process, there are some concepts that we should go over:
- Batch Size: The number of data points (like images or texts) the networks looks at in one iteration. If you need to read 10 pages of a book at a time, then 10 pages is your batch size.
- Epoch: One complete cycle where the network has seen all the training data once. If you have 1000 images and you’ve shown them all to the network, that’s one epochs. During training of the DNN, several epochs should be executed.
- Iteration: One step in the training process where the network updates its knowledge based on a subset of the data.
- Loss Function: A measure of how wrong the network’s predictions are. It is like a score, where the lower, the better.
- Gradients: Directions that tell the network how to adjust its settings to get a better score. Imagine it as feedback on which way go to improve the performance.
- Optimizer: Once we have the gradients from back propagation, we need a strategy or method to adjust the weights of the network. The optimizer is responsible for adjusting them.
- Learning Rate: How much the network changes its settings in each iteration. It’s like deciding how big of a step to take when trying to reach a destination.
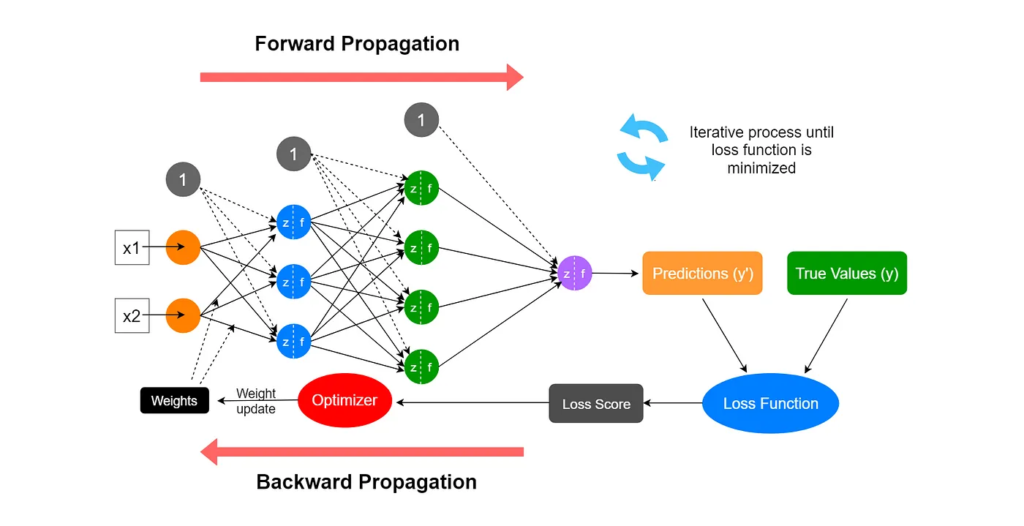
The training process is an iterative process:
- Initialization: The weights and biases of the network are initialized randomly.
- Training loop: In which we do:
- Forward Propagation: Input data (x1, x2) passes through the layers, and the output (y‘) is computed based on current weights and biases. Think of it as asking the network a question and getting an answer.
- Loss Calculation: Based on the Forward Propagation results, is it possible to calculate the error between the predicted (y) and actual outputs (y’), using a loss function, in order to measure the DNN performance.
- Back Propagation: A method used to calculate gradients (based on the loss calculation). It’s like finding out which parts of the network contributed most to the error and also identify how to fix them.
- Weight Update: Optimizers are used to adjust the node’s weights to minimize the loss.
- Evaluate: Repeat until the loss function is minimized.
It is also possible to Fine-Tune an existing model, using the process described previously. During initialization, a already pre-trained model will be used as a starting point.
4. Conclusion
Deep neural networks’ capacity to autonomously learn hierarchical representations is what gives them their power. For instance, DNNs offer solutions because they learn directly from data to identify patterns that humans miss. This skill enables innovations in fields like natural language processing and computer vision.
By automating extremely complex tasks, deep neural networks—the foundation of big language models and many other AI technologies—are causing a disruption in a variety of industries. We can appreciate the creativity of contemporary AI apps more fully if we comprehend their design and training procedures. DNNs continue to be a crucial tool in the AI industry, whether you’re training a network to identify photos or refining a language model to create engaging text.
5. Acknowledgements
I would like to express my gratitude to the authors and creators whose work greatly inspired and informed this post. Special thanks to the creators of the following contents:
- Understanding Deep Neural Networks from First Principles: Logistic Regression
- Train and evaluate deep learning models
- A Beginner’s Guide to Neural Networks: Forward and Backward Propagation Explained
- Deep Neural Networks Tutorial with TensorFlow
- Deep learning is an advanced form of machine learning that tries to emulate the way the human brain learns