
The introduction of the transformer architecture has been one of the most revolutionary developments in the rapidly evolving field of artificial intelligence. The transformer paradigm, first presented by Vaswani et al. in their groundbreaking publication “Attention is All You Need” in 2017, has completely changed natural language processing and more.
An important turning point in the development of natural language processing (NLP) was the introduction of the transformer architecture. This architecture have sparked an explosion in regeneration capabilities by significantly outperforming the previous generation of Recurrent Neural Networks (RNNs), and therefore revolutionizing the way language models comprehend and produce text.
Unlike its predecessor, the transformer architecture relies on self-attention mechanisms to process data sequences more accurately and effectively. Significant improvements in text synthesis, language translation, and numerous other AI applications have resulted from this discovery.
In this article, we intend to explore the basic principles of the transformer architecture, its long-term technical impacts on that evolution, and the way it has re-configured the topography of AI.
1. What is a Large Language Model (LLM)?
The acronym LLM represents “Large Language Model“. It refers to an artificial intelligence model that can comprehend and produce text that is similar to that of a human depending on the input it gets. In order to predict and produce language that is coherent and contextually relevant, these models employ deep learning techniques and are trained on enormous volumes of text data.
LLMs, for instance, can be applied in the following situations:

2. Recurrent Neural Networks
Generative algorithms have long been a part of language modeling, with recurrent neural networks (RNNs) leading the charge in earlier years. An artificial neural network type called a recurrent neural network (RNN) is made to identify patterns in data sequences, including time series, audio, text, and video.
Despite their strength, RNNs were unable to handle the memory and processing demands required for efficient generating tasks. For example, RNNs frequently failed to anticipate the next word since they:
- Required extensive resources to analyze preceding text.
- Often lacked sufficient context to make accurate predictions.
- Were challenged by language complexity, including homonyms and syntactic ambiguity.
3. The transformer architecture
The field of natural language processing was completely transformed in 2017 with the introduction of the transformer architecture. This architecture handles inputs in parallel, scales effectively with multi-core GPUs, and—most importantly—understands the context of words. The notable developments in generative AI that we are currently seeing are a direct result of this discovery.
The transformer architecture overcomes the limitations of RNNs in generative AI in several ways:
Scalability
- RNNs require significant compute and memory resources to perform well at generative tasks.
- In contrast, the transformer architecture can be efficiently scaled to use multi-core GPUs, allowing for larger training datasets and more efficient processing.
Parallel Processing
- The transformer architecture can parallel process input data, which means it can process multiple words simultaneously.
- This parallel processing capability enables faster and more efficient training and inference, making it suitable for generative tasks.
Attention Mechanism
- The transformer architecture introduced the concept of attention, which allows the model to focus on the meaning of the words it is processing.
- The Attention mechanisms enable the model to understand the context and relationships between words in a sentence or document.
Transformers are composed of two main components: the encoder and the decoder, which work in tandem. The architecture, as derived from the original “Attention is All You Need” paper, processes inputs at the bottom and outputs at the top, emphasizing a clear flow of information:
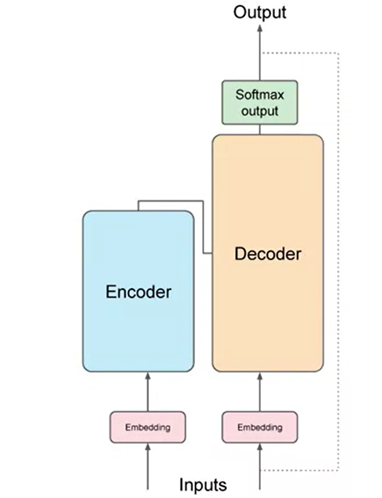
- Before passing texts into the model, the words are tokenized and converted into numbers using a tokenizer.
- These numbers are then passed to the embedding layer, where each token is represented as a vector in a high-dimensional space.
- The positional encoding is added to preserve the word order.
- The self-attention layer analyzes the relationships between the tokens in the input sequence, allowing the model to capture contextual dependencies.
- The transformer architecture has multiple sets of self-attention weights, known as attention heads, which learn different aspects of language.
- The output of the self-attention layer is processed through a fully-connected feed-forward network, and the resulting logits are normalized into probability scores for each word.
3.1. How does it actually work?
You have been introduced to the major components of the transformer architecture. However, you might still be wondering how the prediction process actually works from start to finish.
In this walkthrough, we’ll explore a simple example using a transformer model for a translation task (which was the original goal of the transformer architecture designers). Let’s translate a French phrase into English using a transformer model. This task is an example of a sequence-to-sequence process:
- Tokenization: First, the French input phrase is tokenized using the same tokenizer that was employed during the model’s training phase.
- Encoding: The tokens are fed into the encoder side of the network. They pass through an embedding layer and proceed through multi-headed attention layers. The encoder’s feed-forward network processes these outputs, resulting in a deep representation of the input sequence’s structure and meaning.
- Decoding: To affect the decoder’s self-attention mechanisms, this deep representation is subsequently incorporated into it. When the decoder receives a start-of-sequence token as input, it is prompted to use the contextual information from the encoder to predict the subsequent token.
- Generating the Output: The first token is created by processing the decoder’s predictions via its feed-forward network and a final softmax output layer. Until an end-of-sequence token is anticipated, this procedure is repeated, with each output token being fed back into the input to create the subsequent token.
- Detokenization: To finalize the translation, the token sequence is transformed back into words. The result could be, for instance, “I love machine learning.”
3.2. Different Transformer Variants
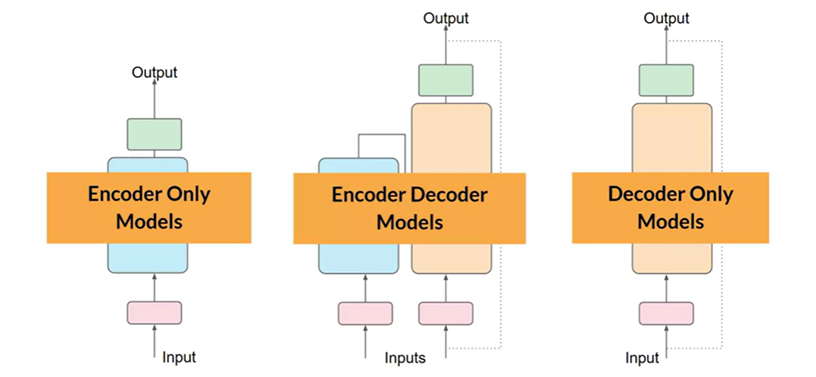
Transformers contain encoder and decoder components, that can be used together or separately:
- Encoder-Only Models: These models, such as BERT, encode input sequences to perform tasks like sentiment analysis. They typically require additional layers to handle classification tasks. BERT is a popular example.
- Encoder-Decoder Models: These models are mostly used in sequence-to-sequence tasks such as translation, where input and output sequences differ in length. They can also be used for general text generation tasks. Popular examples include BART and T5,.
- Decoder-Only Models: These models are quite flexible and capable of generalizing across numerous tasks due to their scalability. Popular examples include the GPT family, BLOOM, Jurassic, and LLaMA.
3.3. The Attention Mechanism: A Key Innovation in Transformers
One of the most fundamental component of the transformer architecture is the attention mechanism. It has revolutionized how models process and understand sequences of data.
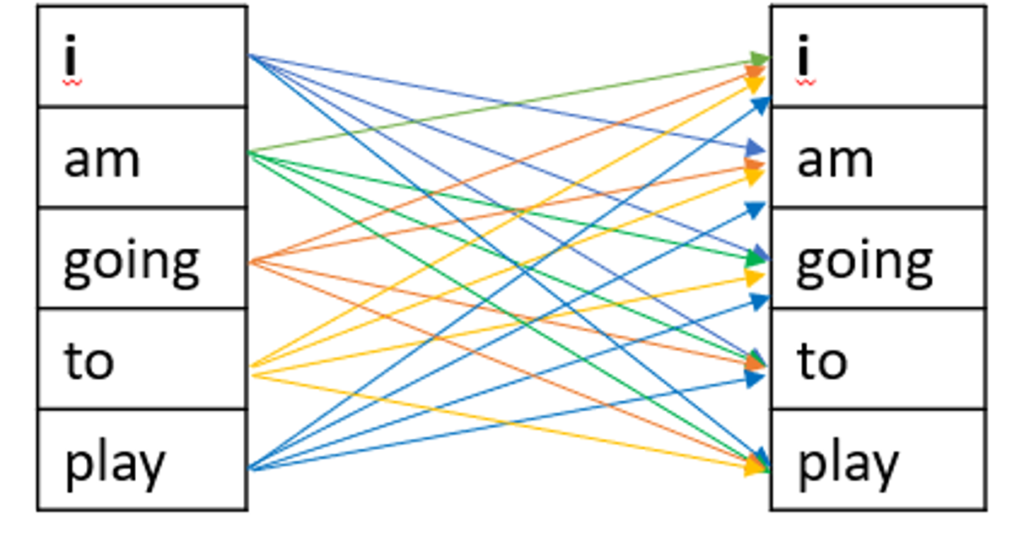
The self-attention mechanism allows a model to weigh the importance of different words in a sequence relative to each other. This means that, rather than processing each word in isolation or only in the context of its immediate neighbors, the model can consider the entire sequence of words. This capability enables it to capture long-range dependencies and contextual relationships between words more effectively.

Here’s how it works:
- Input Representation: Each word in the input sequence is represented as a vector in a high-dimensional space.
- Attention Scores: For each word, the model calculates attention scores with respect to every other word in the sequence. These scores determine how much focus each word should receive when producing the output.
- Weighted Sum: The input vectors are combined into a weighted sum based on these attention scores, effectively creating a new representation of each word that incorporates its context within the entire sequence.
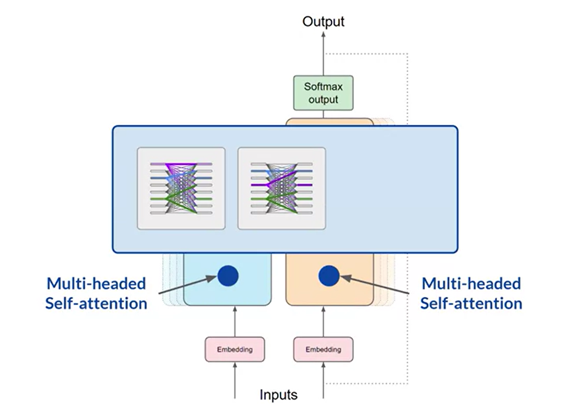
Another of the key innovations of transformers is the use of multi-headed self-attention:
- Instead of calculating a single set of attention scores, the model computes multiple sets in parallel, known as “heads.”
- Each head can learn different aspects of the input sequence, such as syntax, semantics, or relationships between specific entities.
- This allows the model to develop a richer understanding of the data.
4. Conclusion
The transformer architecture has undeniably been a “Game Changer”, revolutionizing the field of artificial intelligence, particularly in natural language processing. By addressing the limitations of previous models like RNNs and introducing groundbreaking concepts such as self-attention and parallel processing, transformers have set new standards for efficiency and scalability. Their versatility is evident in applications ranging from machine translation to advanced language modeling, paving the way for state-of-the-art systems like GPT, BERT, and T5.
As we continue to witness the rapid evolution of AI technologies, the transformer architecture remains a cornerstone, inspiring further innovations and expanding the boundaries of what AI can achieve. By unlocking the potential to understand and generate human-like language, transformers not only enhance our tools and applications but also deepen our understanding of intelligence itself.
This architecture has not just reshaped the landscape of NLP, but it ultimately has redefined the possibilities of AI as a whole.