
Have you ever wondered how those intelligent chatbots and virtual assistants seem to understand exactly what you’re asking? A lot of that magic comes from a process called fine-tuning, and today, we’re going to explore what that means and why it’s so important.
1. The importance of Fine-Tuning
Imagine you’ve got a massive library filled with general knowledge—kind of like a pre-trained model. It’s impressive, but when you need specific advice, like how to bake the perfect sourdough bread or the best way to train for a marathon, you need to dig a little deeper.
Fine-tuning is like taking that vast knowledge and tailoring it for a specific task, making the model not just a jack-of-all-trades, but a master of one. This process helps update the model’s weights, allowing it to become more adept at specific tasks you care about.
By training the model with examples that illustrate the desired responses, the model learns to follow these instructions more effectively. As the model processes this data, its weights are adjusted based on the calculated loss. The result is a new version of your model, now fine-tuned and better suited for the tasks you’re interested in.

2. Train or fine-tune a LLM?
You might be wondering, why not just train a model from scratch for every task? Well, think about it like baking. You could make bread by growing your own wheat and milling it into flour (training from scratch), or you could start with a pre-made dough and just add your favorite herbs and spices (fine-tuning).
Here’s a detailed discussion of the pros and cons of each approach:
| Approach | Pros | Cons |
|---|---|---|
| Training an LLM from Scratch | – Allows for the design of a model architecture and training process tailored to specific needs and objectives, which can be beneficial for novel applications or research. – Provides complete control over the training data, ensuring that the model is trained with specific content, quality, and biases in mind. – Offers the opportunity to experiment with new architectures, training techniques, and optimization strategies that could lead to advancements in the field. | – Requires significant computational resources, including powerful hardware and substantial time, to process large volumes of data. – Involves complex engineering challenges, including data preparation, model design, and hyperparameter tuning, which require specialized expertise. – The costs associated with training from scratch can be prohibitive, especially when considering the infrastructure and personnel required. |
| Fine-Tuning an Existing LLM | – Significantly reduces the computational resources and time required compared to training from scratch, as the model has already learned general language patterns. – Lower costs are involved since the foundational training phase, which is resource-intensive, has already been completed. – Builds upon a model that is already known to perform well on general NLP tasks, providing a solid starting point for task-specific applications. – Allows for faster deployment of models in real-world applications, as fine-tuning can be completed relatively quickly. | – Less flexibility in modifying the architecture or training process, which might limit the ability to tailor the model to very specific or novel needs. – The pre-trained model may carry biases or limitations inherent in the original training data, which can affect the fine-tuned model. – There is a potential risk of overfitting to the fine-tuning dataset, especially if it is small or not representative of the intended application domain. |
Based on the list of Pros and Cons identified previously, training from scratch is often chosen for groundbreaking research or when developing models for unique languages or applications, while fine-tuning is typically preferred for practical applications where efficiency and leveraging existing capabilities are prioritized.
Usually, most companies and researchers opt for fine-tuning because it’s faster and makes use of the hard work already done by others.
3. LLM Evaluation Metrics
You might be asking how do you know if your fine-tuned model is any good? That’s where evaluation metrics come in. Think of them as taste testers. Metrics like ROUGE and BLEU score help us objectively measure how well the model’s outputs match the desired results. This is crucial when you’re fine-tuning for tasks like summarizing articles or translating text, ensuring your model isn’t just accurate but also fluent and coherent.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- Used to evaluate text summarization
- Compares a summary to one or more reference summaries.
- Higher ROUGE scores indicate better overlap with the reference text, suggesting that the model-generated text is capturing important content.
BLEU (Bilingual Evaluation Understudy)
- Used for text translation.
- Compares to human-generated translations.
- BLEU primarily focuses on precision and may not capture semantic meaning or fluency as effectively as human judgment would.
In summary, ROUGE and BLEU are valuable tools for evaluating LLM-generated text, each with its strengths and limitations. They provide quantifiable measures of text quality but should ideally be part of a broader evaluation strategy that includes human assessments.
To measure and compare LLMs more comprehensively, you can use pre-existing datasets and benchmarks specifically designed for this purpose:
- Benchmarks such as GLUE, SuperGLUE cover a wide range of tasks and scenarios:
- GLUE is a collection of natural language tasks, while SuperGLUE includes more challenging versions of tasks not included in GLUE.
- Both benchmarks have leaderboards for comparing and contrasting evaluated models.
- Other benchmarks like Massive Multitask Language Understanding (MMLU), BIG-bench, and Holistic Evaluation of Language Models (HELM) push LLMs further by testing their abilities in various domains and scenarios:
- MMLU tests models on tasks beyond basic language understanding, while BIG-bench consists of 204 tasks covering different fields.
- HELM aims to improve model transparency and assesses metrics beyond basic accuracy, including fairness, bias, and toxicity.
By understanding and utilizing these benchmarks, you can effectively evaluate and compare the performance of these fine-tuned LLMs and gain insights into their capabilities.
4. Catastrophic Forgetting
Fine-tuning allows us to focus on a single task instead of performing multiple language tasks. However, there is a potential downside called catastrophic forgetting, where the model may forget how to perform other tasks after fine-tuning.
Imagine if, while learning to bake sourdough, you suddenly forgot how to make a simple sandwich loaf. This can happen to models too—they might lose some of their general knowledge while focusing on a specific task. To avoid catastrophic forgetting, you can take advantage of the following techniques (among others):
- Perform multitask fine-tuning: This involves fine-tuning the model on multiple tasks simultaneously. It requires more data and compute but helps maintain the model’s multitask capabilities.
- Perform parameter efficient fine-tuning (PEFT): PEFT preserves the weights of the original language model and trains only a small number of task-specific adapter layers and parameters. This approach shows great robustness to catastrophic forgetting.
5. Advanced Fine-Tuning Techniques
Now, let’s talk about some cool techniques that make fine-tuning even more efficient.
5.1 Parameter Efficient Fine-Tuning (PEFT)
It’s like having a smart dough mixer that only kneads certain parts of the dough, saving energy. Parameter Efficient Fine-Tuning (PEFT) is an approach designed to adapt large pre-trained models to new tasks with minimal computational cost and memory usage. This method focuses on updating only a small subset of the model’s parameters, allowing for efficient and effective fine-tuning. Here’s a closer look at PEFT.
There are three main classes of PEFT methods:
- Selective methods: PEFT involves fine-tuning only specific parts of the model, such as certain layers or additional modules, rather than the entire model. This selective approach helps retain the original knowledge captured during pre-training.
- Reparameterization methods: PEFT uses Low-Rank Adaptation (LoRA) that involves applying low-rank updates to the model’s weight matrices. By focusing on these compact updates, LoRA reduces the number of parameters that need to be adjusted, maintaining computational efficiency.
- Additive methods:
- Adapters are small, trainable modules added to each layer of the model. During fine-tuning, only these adapters are trained while the original model parameters remain fixed. This allows the model to learn task-specific information without altering its foundational knowledge.
- Soft prompts involve the addition of continuous embeddings (soft prompts) to the input of a pre-trained model, guiding it to perform specific tasks without altering its parameters.

Advantages of PEFT:
- Efficiency: By updating only a small number of parameters, PEFT significantly reduces the computational and memory requirements, making it feasible to fine-tune large models on devices with limited resources.
- Preservation of Knowledge: Since most of the model’s parameters remain unchanged, PEFT helps maintain the knowledge and capabilities learned during the initial pre-training phase, reducing the risk of catastrophic forgetting.
- Flexibility: PEFT allows for quick adaptation to multiple tasks without the need for extensive retraining. This flexibility is particularly useful in environments where models need to be frequently updated or deployed for various applications.
- Scalability: PEFT techniques are scalable, allowing the fine-tuning of very large models, such as those with billions of parameters, in a practical and resource-conscious manner.
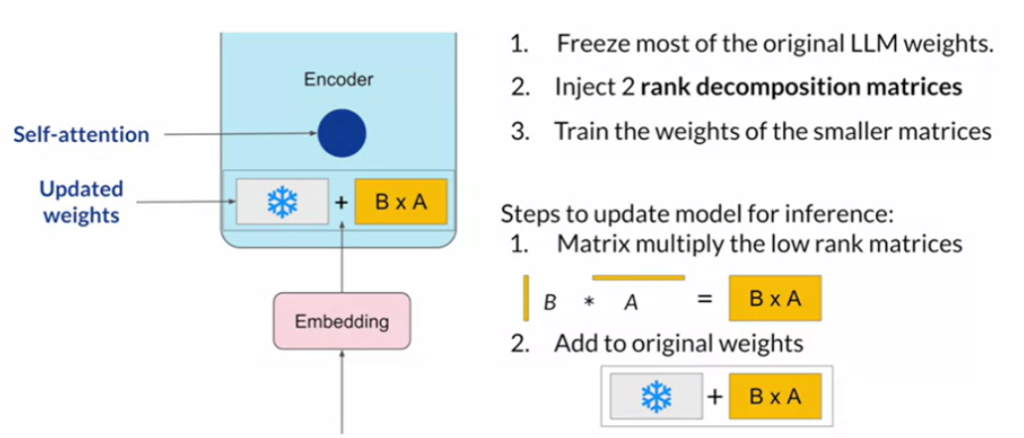
5.2 Low-Rank Adaptation (LoRA)
Imagine updating your recipe with just a few tweaks instead of rewriting it completely. LoRA does this by focusing on low-rank updates to the model’s weights, which is especially handy for large models where full updates would be too costly. In fact, LoRA focuses on making the adaptation of large models more resource-efficient by using low-rank matrices to approximate the changes needed in the model’s weights. This approach allows for fine-tuning without the computational expense of adjusting the entire set of model parameters.
How LoRA Works:
- Low-Rank Decomposition: LoRA introduces two smaller matrices that, when multiplied together, approximate the updates needed for the original weight matrices. This decomposition significantly reduces the number of parameters involved in the adaptation process.
- Integration with Pre-trained Models: Instead of modifying all the parameters of a pre-trained model, LoRA applies these low-rank updates to only a portion of the weights. This selective updating preserves most of the pre-trained model’s knowledge, ensuring that it retains its general capabilities while adapting to new tasks.
- Parameter Efficiency: By focusing on low-rank updates, LoRA dramatically reduces the memory and computational requirements needed for fine-tuning. This makes it possible to adapt large models even on devices with limited resources.
5.3 Other interesting training and optimization techniques
- Prompt Tuning: This method involves adjusting the input prompts to guide the model’s responses more effectively. By refining how prompts are presented, developers can influence the model’s output without altering its internal parameters.
- Reinforcement Learning from Human Feedback (RLHF): RLHF combines reinforcement learning with human feedback to improve model behavior. By optimizing the model’s responses based on human evaluations, RLHF enhances the alignment of the model’s actions with desirable outcomes, focusing on helpfulness and accuracy.
- Constitutional AI: This approach involves setting explicit guidelines or “constitutions” that the model must follow, helping it adhere to ethical standards and avoid harmful behavior. These guidelines are integrated into the training process to guide the model’s decision-making.
6. Hands-on
If you are eager to dive into fine-tuning a pre-trained model, check out this comprehensive tutorial.
It provides a step-by-step guide to loading and preparing a dataset, selecting a suitable pre-trained model, and setting up training arguments for fine-tuning. You’ll learn how to effectively customize the model for text generation.
The tutorial also covers how to evaluate the model’s performance and save it for future use, enabling you to leverage the power of large pre-trained models to achieve optimal results on your dataset with efficiency and ease.
7. Conclusion
In the end, fine-tuning is about making those already smart models even smarter for specific tasks. Whether it’s helping Alexa play your favorite song with better accuracy or allowing Grammarly to understand the nuances of your writing style, fine-tuning is the secret sauce.
So next time you marvel at how well your virtual assistant understands you, remember: it’s all thanks to the intricate process of fine-tuning. It’s a fascinating world where efficiency meets precision, helping to make technology work seamlessly with human needs.